|
How to pronounce my name?Lihe -> lee-huh. Hi there, thanks for visiting my website! I am a M.Sc. student (Sep. 2023 - Now) at the School of Artificial Intelligence at Nanjing University, where I am fortunate to be advised by Prof. Yang Yu and affiliated with the LAMDA Group led by Prof. Zhi-Hua Zhou. Specifically, I am a member of the LAMDA-RL Group, which focuses on reinforcement learning research. Prior to that, I obtained my bachelor's degree at the same school and university in June 2023. Unity makes strength. Currently my research interest is Reinforcement Learning (RL), especially in Multi-agent Reinforcement Learning (MARL) that enables agents efficiently, robustly and safely coordinate with other agents🤖 and even humans👨👩👧👦. Please feel free to drop me an Email for any form of communication or collaboration!
Email:
CV / Google Scholar / Semantic Scholar / DBLP / Github / Twitter |

Just a reminder, I am the guy on the left. |
|
|
|
|
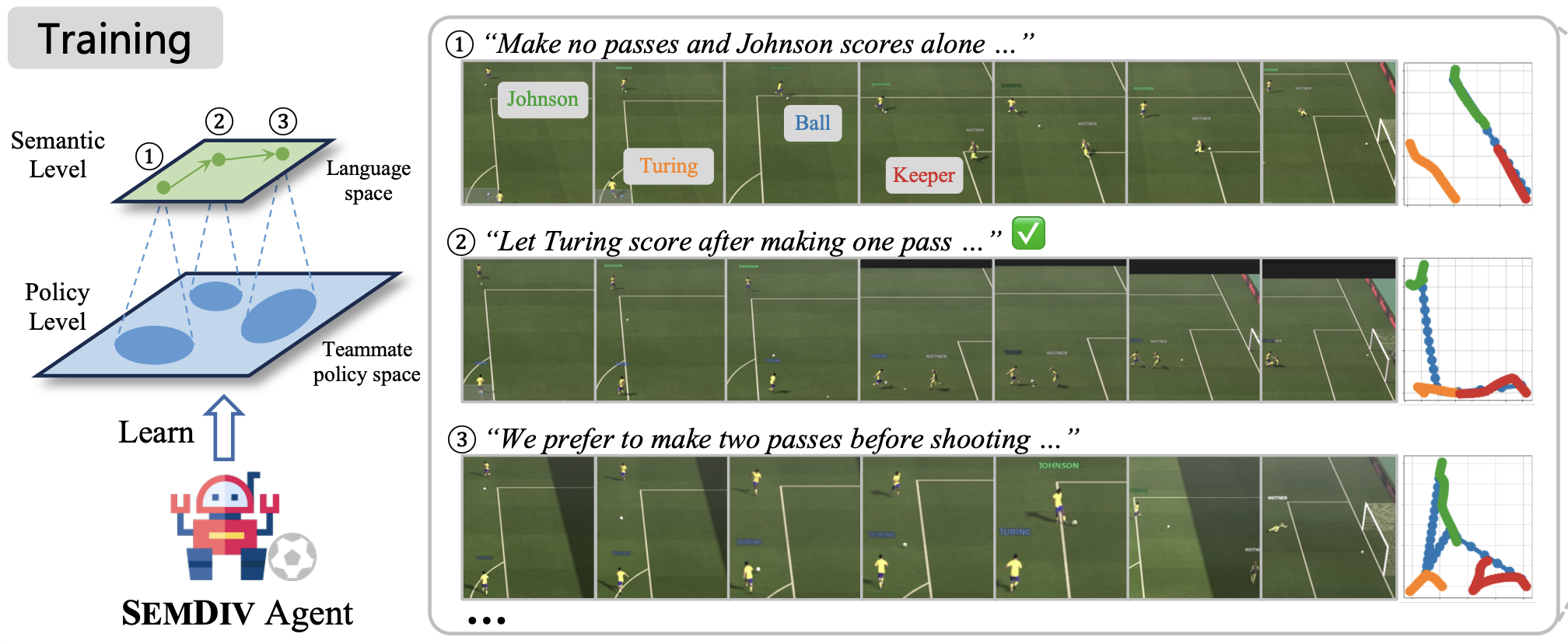
Lihe Li, Lei Yuan, Pengsen Liu, Tao Jiang, Yang Yu The 42rd International Conference on Machine Learning (ICML), 2025 pdf / link / code / bibtex Instead of discovering novel teammates only at the policy level, we utilize LLMs to propose novel coordination behaviors described in natural language, and then transform them into teammate policies, enhancing teammate diversity and interpretability, eventually learning agents with language comprehension ability and stronger collaboration skills. |
|
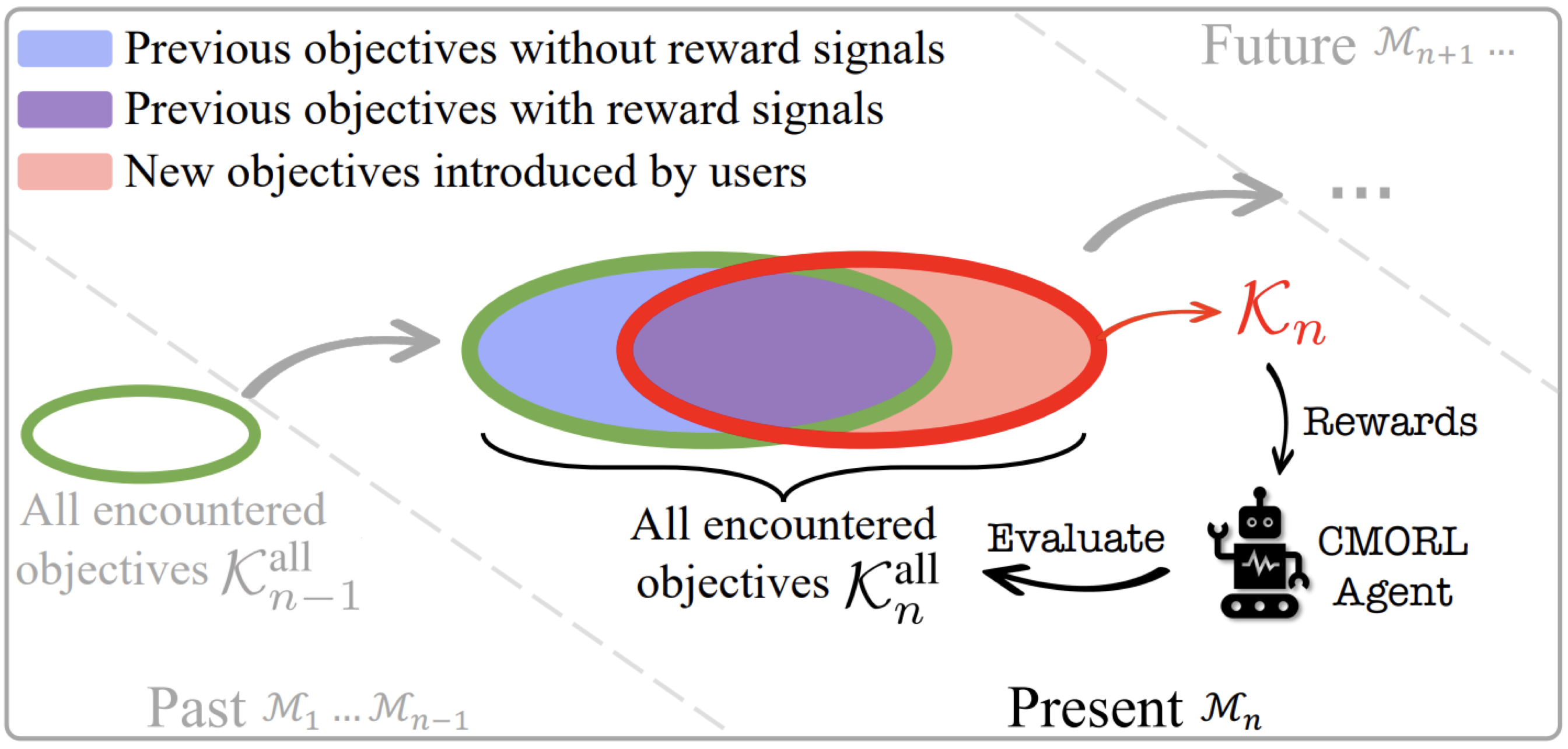
Lihe Li, Ruotong Chen, Ziqian Zhang, Zhichao Wu, Yi-Chen Li, Cong Guan, Yang Yu, Lei Yuan The 33rd International Joint Conference on Artificial Intelligence (IJCAI), 2024 pdf / link / code / talk / poster / bibtex We study the problem of multi-objective reinforcement learning (MORL) with continually evolving learning objectives, and propose CORe3 to enable the MORL agent rapidly learn new objectives and avoid catastrophic forgetting about old objectives lacking reward signals. |
|
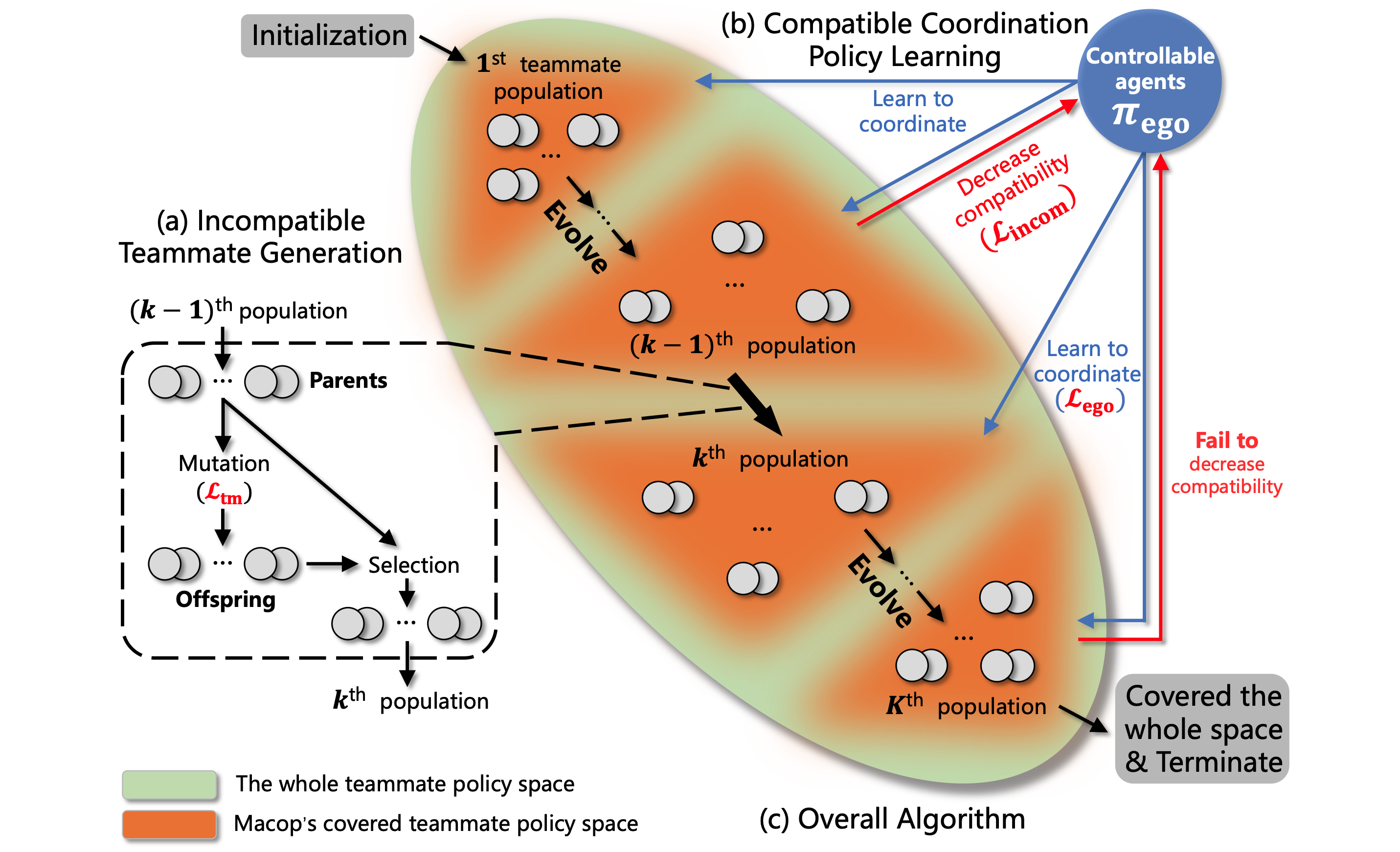
Lei Yuan, Lihe Li, Ziqian Zhang, Feng Chen, Tianyi Zhang, Cong Guan, Yang Yu, Zhi-Hua Zhou Proceedings of the Fifth International Conference on Distributed Artificial Intelligence (DAI), Best Paper Award, 2023 pdf / link / code / English talk / Chinese talk / bibtex We propose Multi-agent Compatible Policy Learning (MACOP), where we adopt an agent-centered teammate generation process that gradually and efficiently generates diverse teammates covering the teammate policy space, and we use continual learning to train the ego agents to coordinate with them and acquire strong coordination ability. |
|
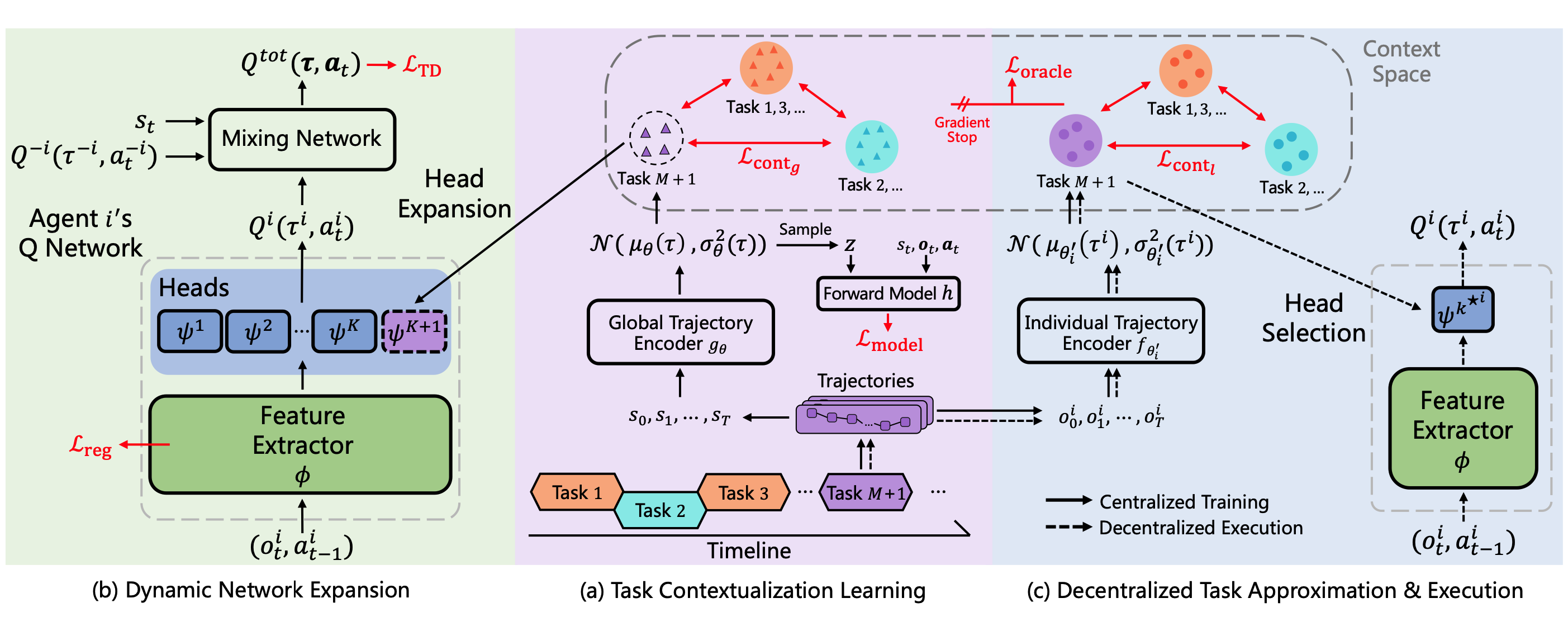
Lei Yuan, Lihe Li, Ziqian Zhang, Fuxiang Zhang, Cong Guan, Yang Yu IEEE Transactions on Neural Networks and Learning Systems (TNNLS) pdf / link / code / poster / bibtex We formulate the continual coordination framework and propose MACPro to enable agents to continually coordinate with each other when the dynamic of the training task and the multi-agent system itself changes over time. |
|
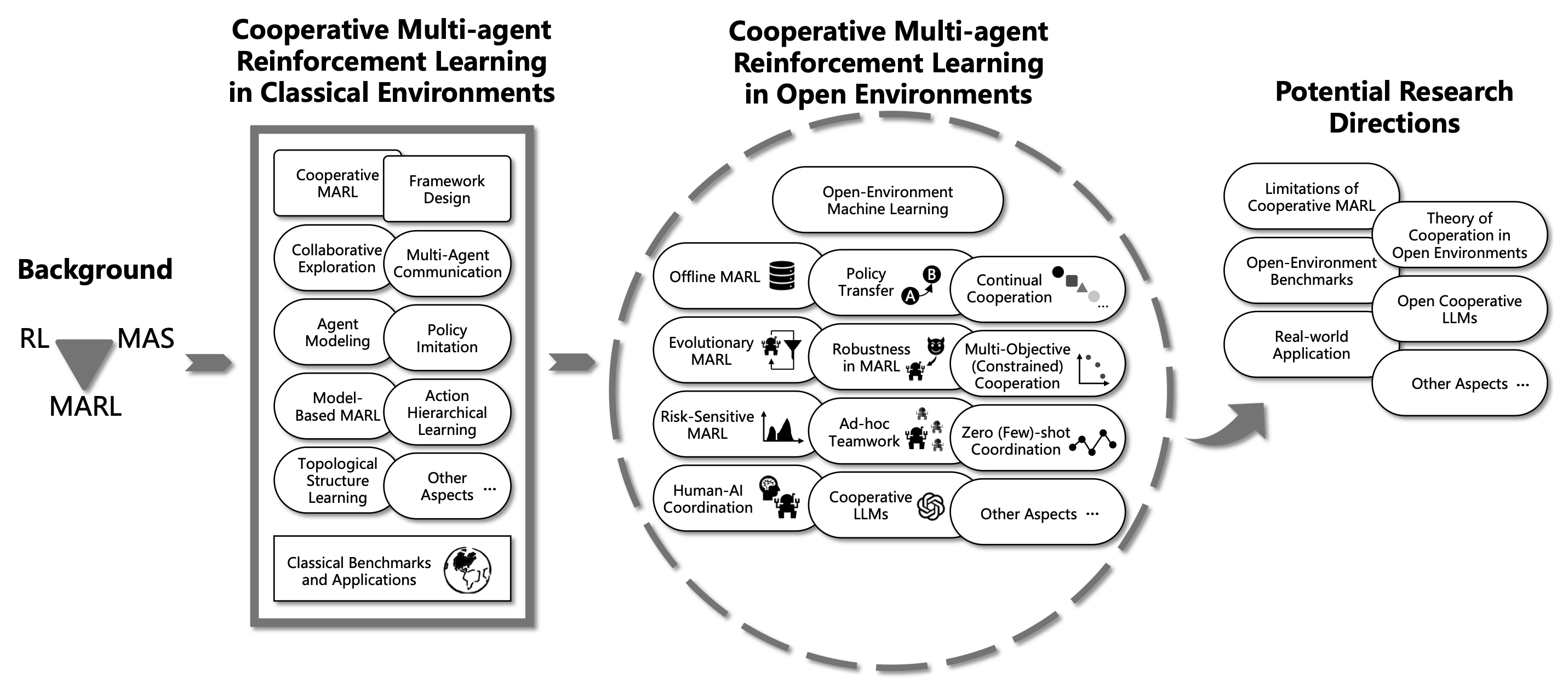
Lei Yuan, Ziqian Zhang, Lihe Li, Cong Guan, Yang Yu Science China Information Sciences (SCIS) pdf in English / pdf in Chinese / link / bibtex We review multi-agent cooperation from closed environment to open environment settings, and provide prospects for future development and research directions of cooperative MARL in open environments. |
|
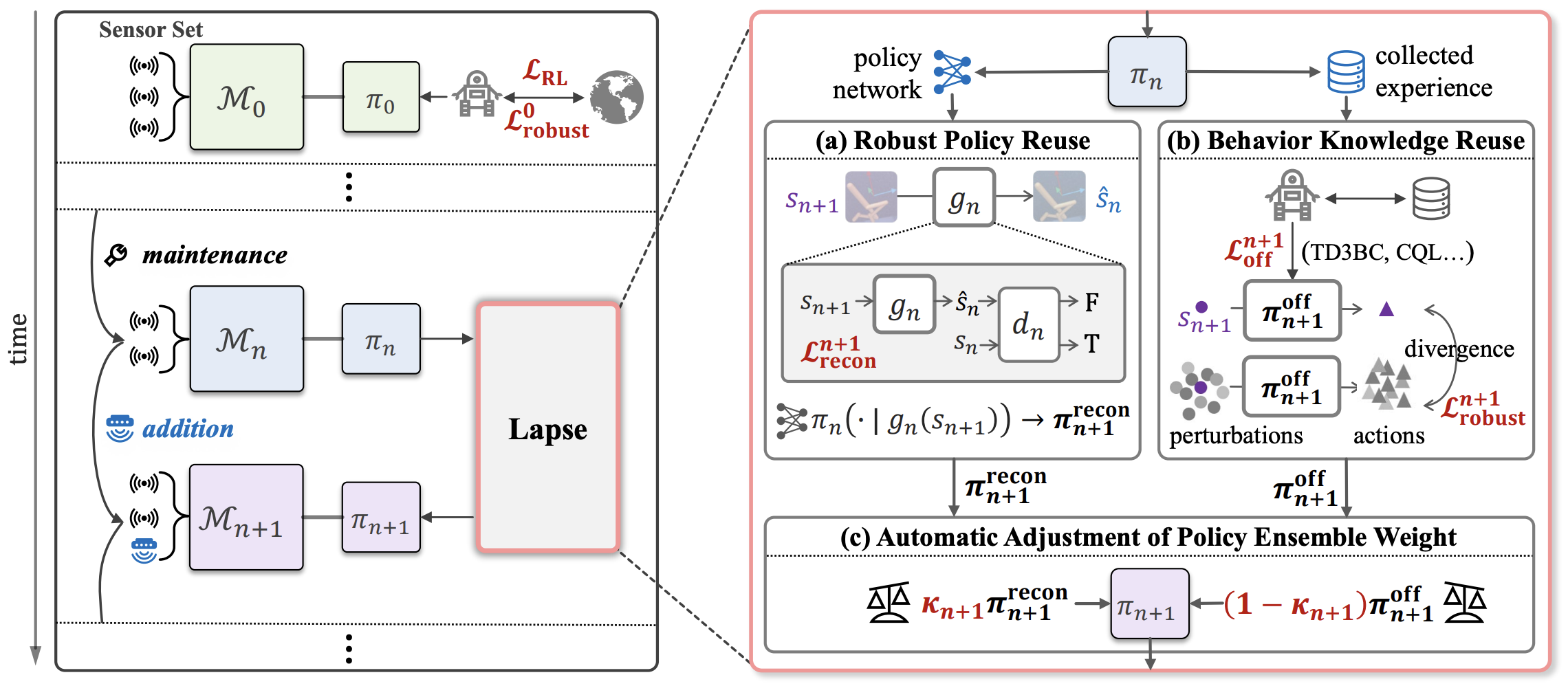
Ziqian Zhang, Bohan Yang, Lihe Li, Yuqi Bian, Ruiqi Xue, Feng Chen, Yi-Chen Li, Lei Yuan, Yang Yu The 42rd International Conference on Machine Learning (ICML), 2025 pdf / link / bibtex We addresse the performance degradation of RL policies when state features (e.g., sensor data) evolve unpredictably by proposing Lapse, a method that reuses old policies by combining them with a state reconstruction model for vanished sensors and leverages past policy experience for offline training of new policies. |
|
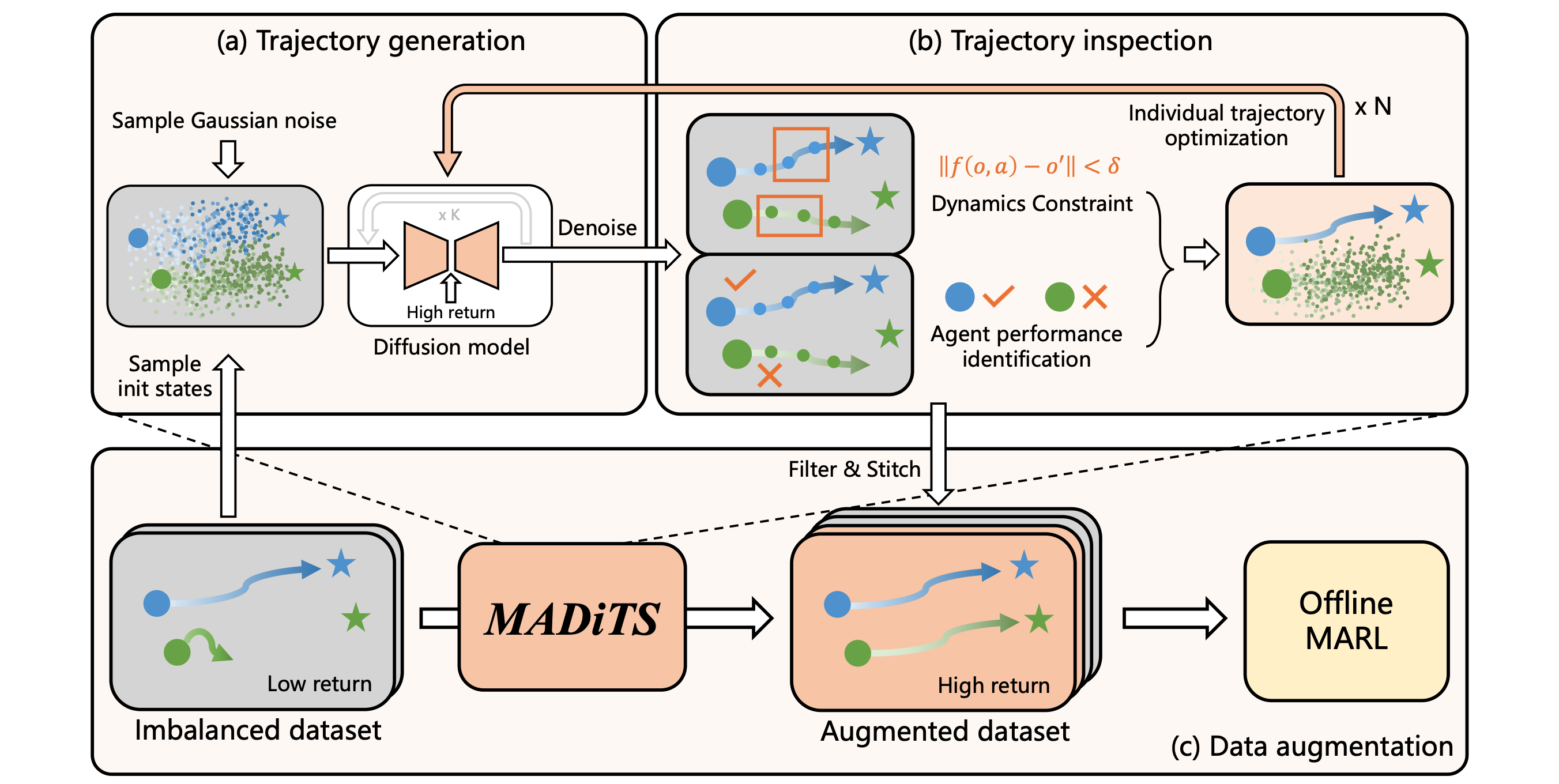
Lei Yuan, Yuqi Bian, Lihe Li, Ziqian Zhang, Cong Guan, Yang Yu The 13th International Conference on Learning Representations (ICLR), 2025 pdf / link / bibtex We propose a data augmentation technique for offline cooperative MARL, utlizing diffusion models to improve the quality of the datasets. |
|
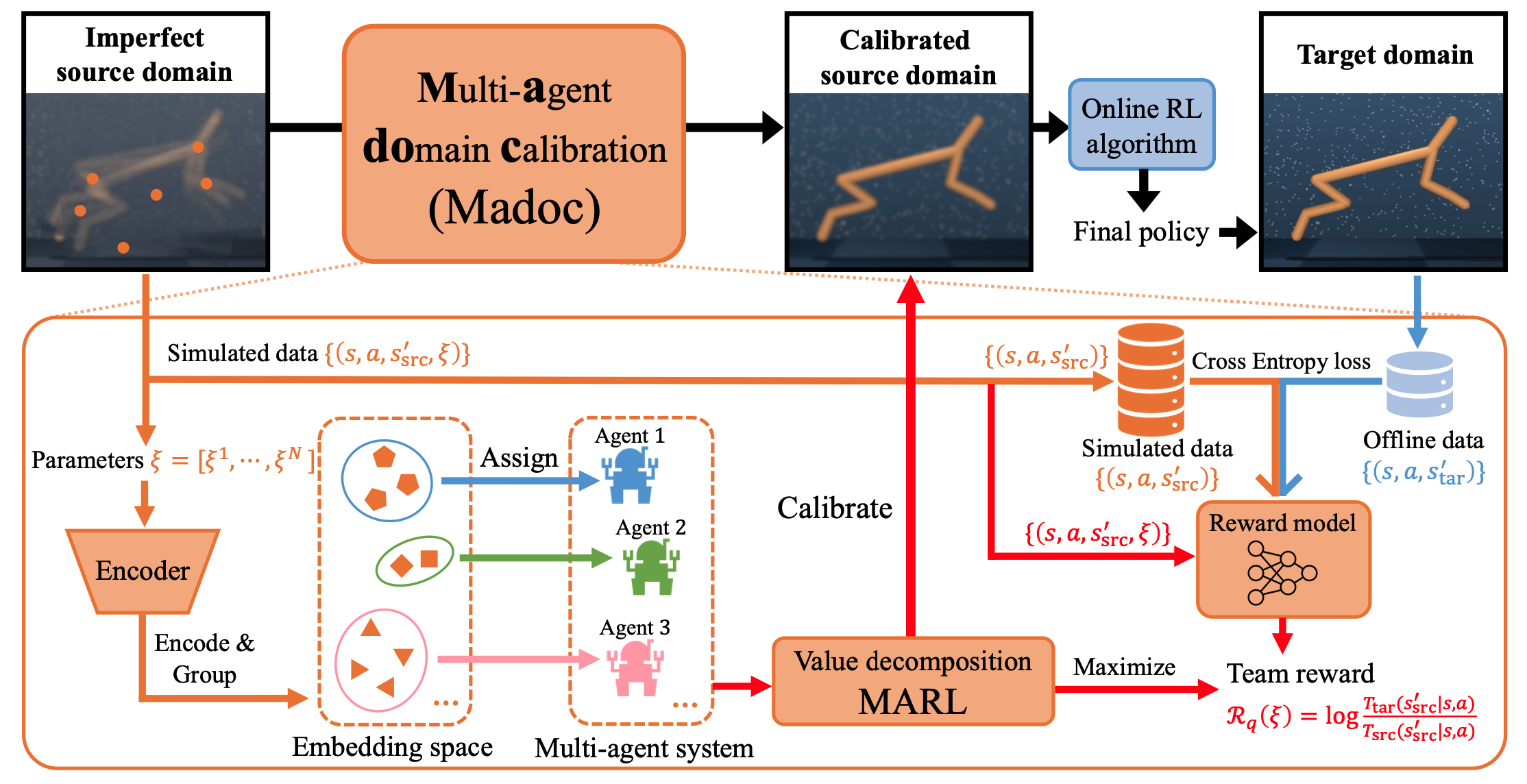
Tao Jiang, Lei Yuan, Lihe Li, Cong Guan, Zongzhang Zhang, Yang Yu Advances in Neural Information Processing Systems 38 (NeurIPS), 2024 pdf / link / code / bibtex We formulate domain calibration as a cooperative MARL problem to improve efficiency and fidelity. |
|
|
 |
Nanjing University
2023.09 - present M.Sc. in Computer Science and Technology Advisor: Prof. Yang Yu |
|
Nanjing University
2019.09 - 2023.07 B.E. in Artificial Intelligence Advisor: Prof. Yang Yu |
 |
Guangdong Zhaoqing Middle School
2016.09 - 2019.06 |
|
|
|
|
|
 lately.
lately.
{kind=link}
{kind=link}
|
Template courtesy: Jon Barron. |